0
OCR Text Detection Tool
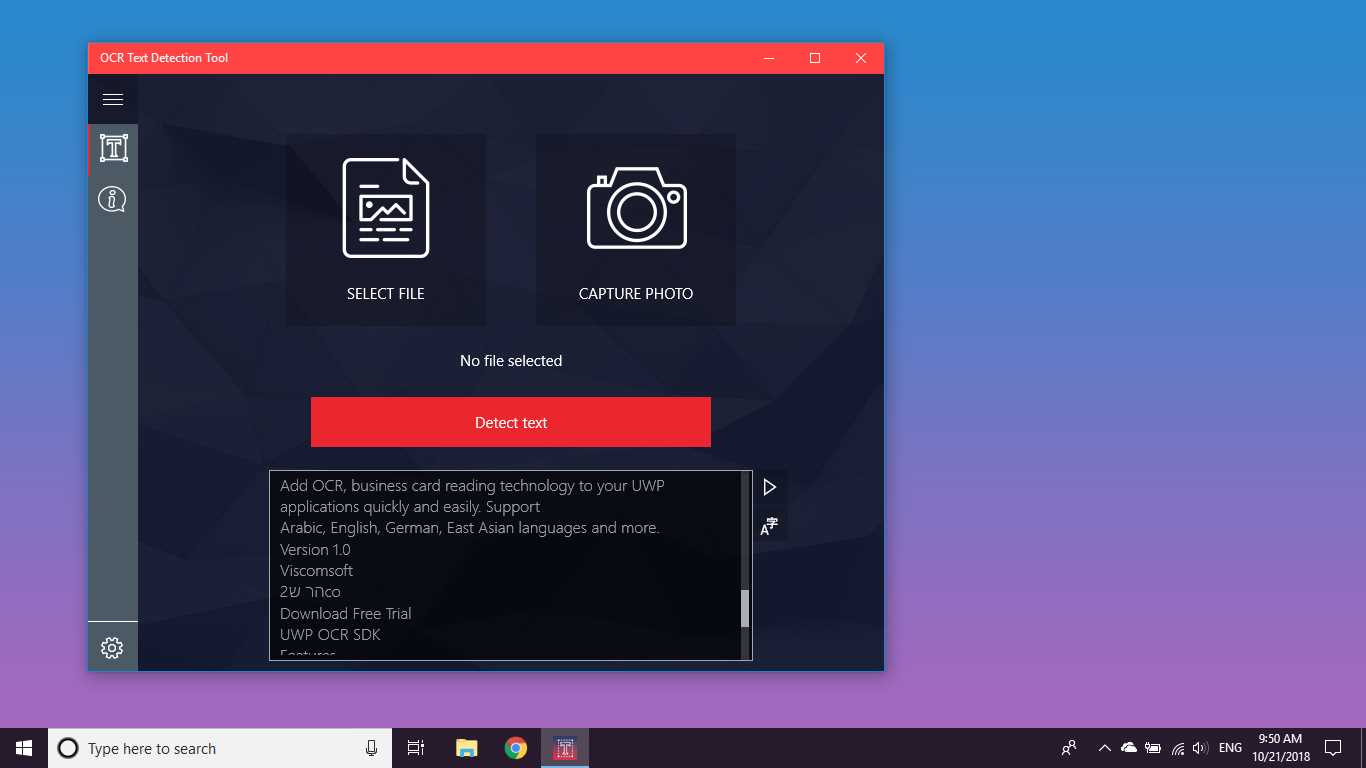
تشخیص متن دقیق و سریع از هر پرونده تصویری که از دستگاه شما بارگیری شده است یا با یک عکس فوری گرفته شده است.همچنین از تشخیص متنی یک PDF و تشخیص دست خط و ترجمه متن به 114 زبان مختلف پشتیبانی می کند.
- نرم افزار رایگان
- Windows S
- Windows
- Windows Mobile
- Windows Phone
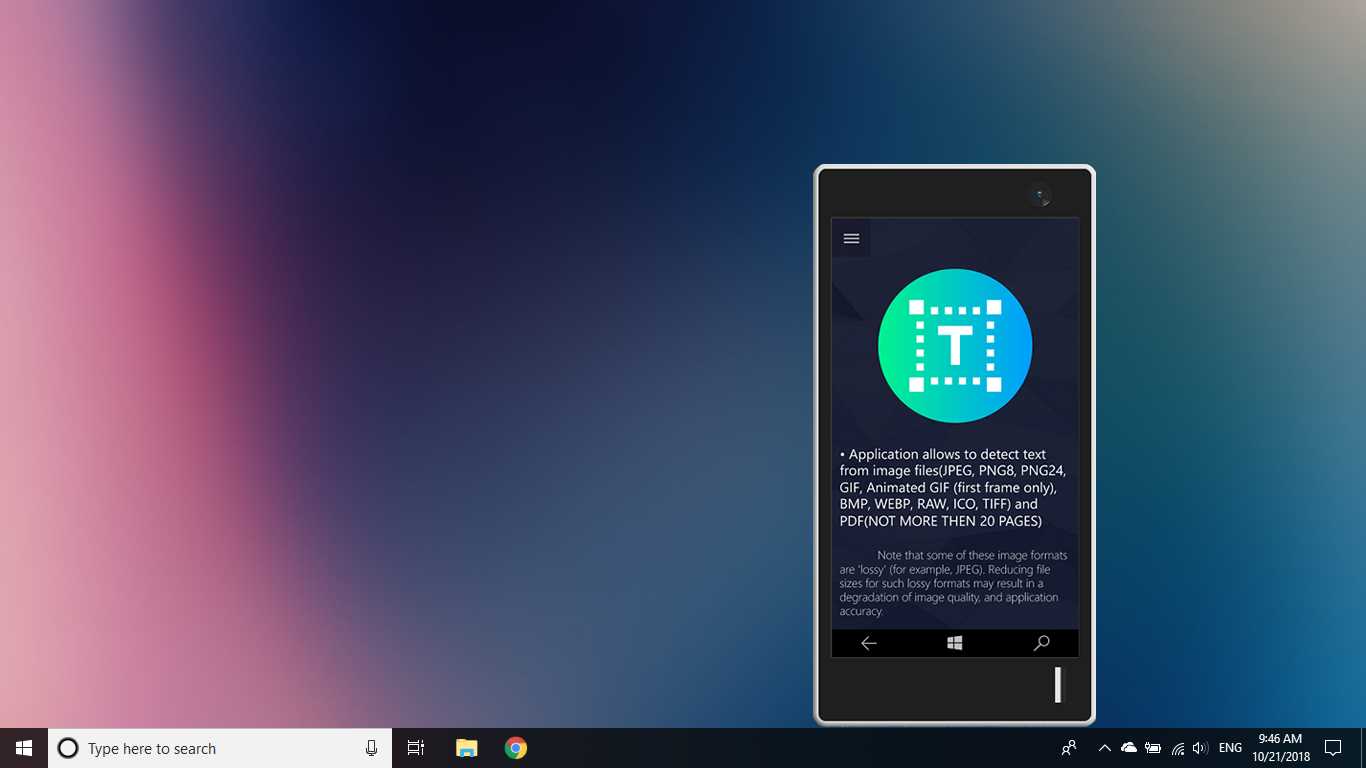
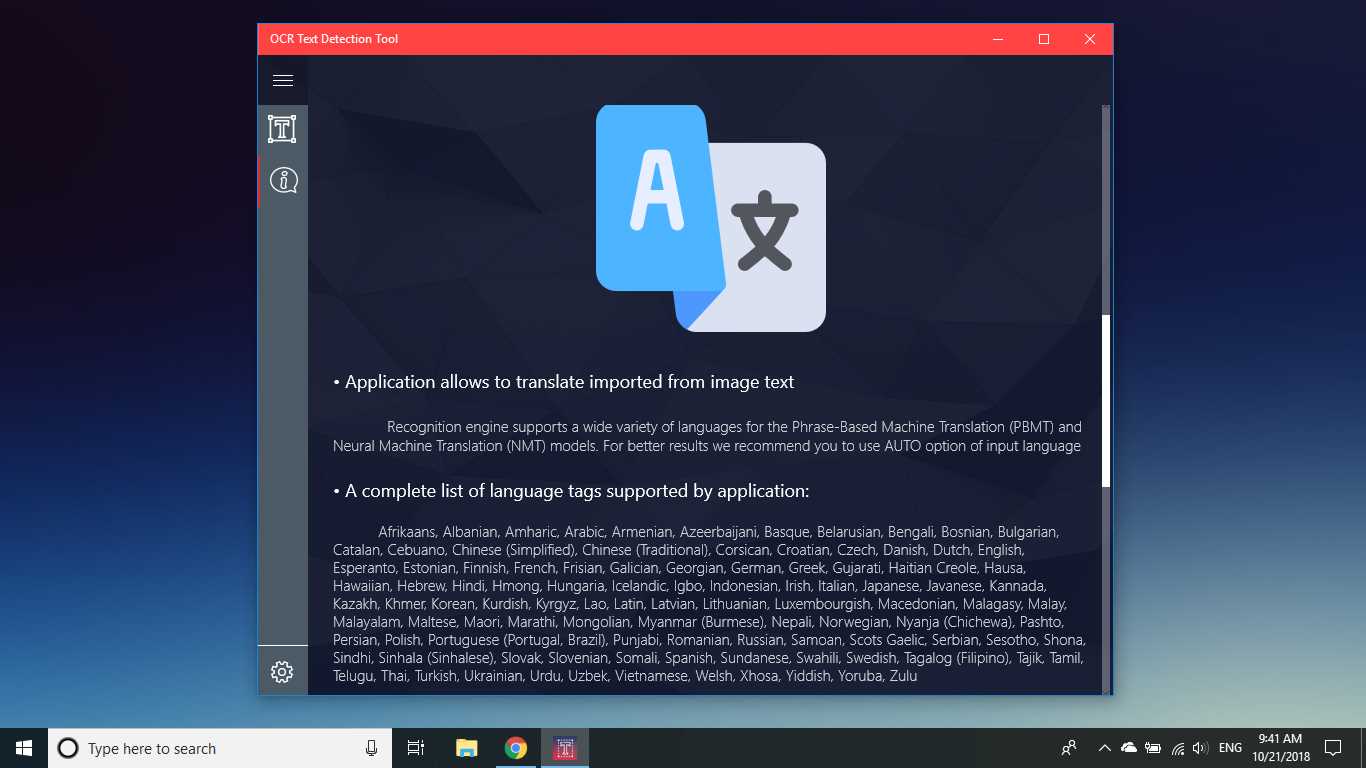
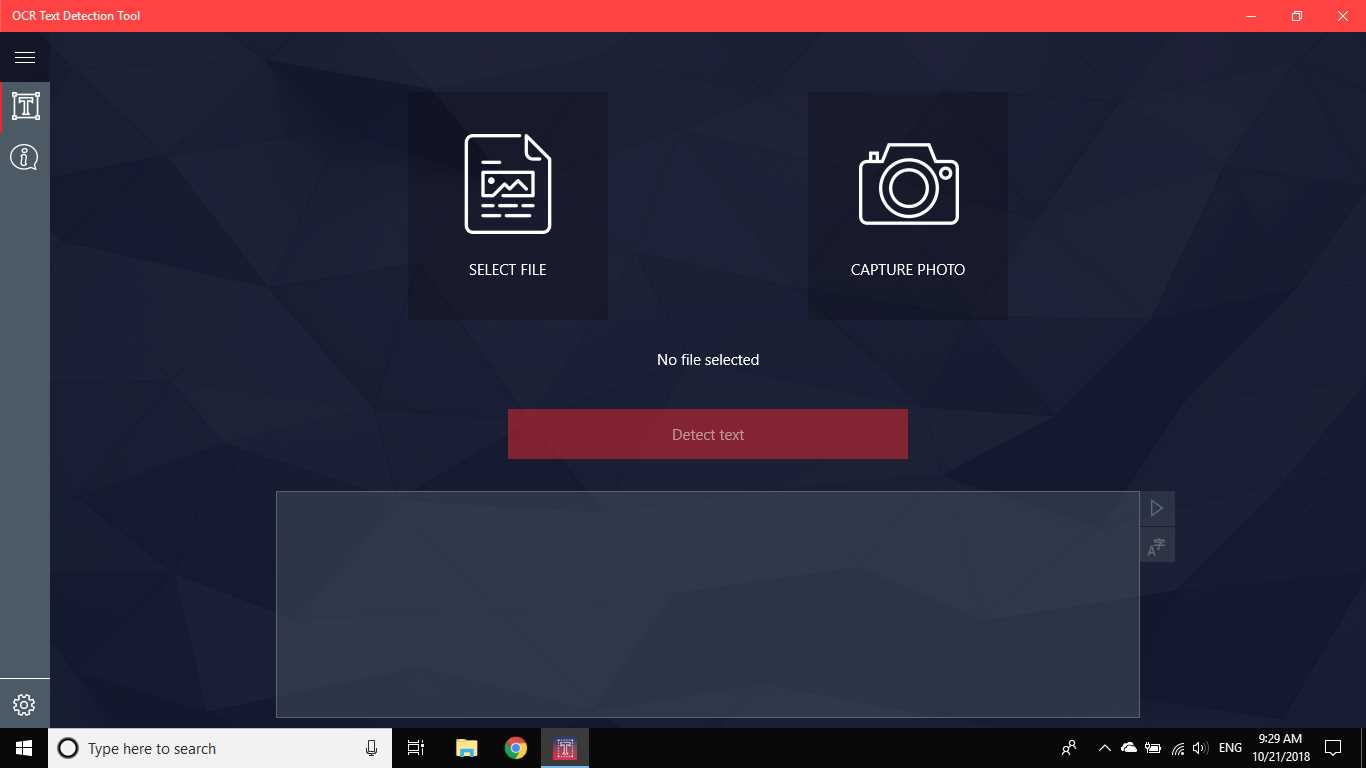
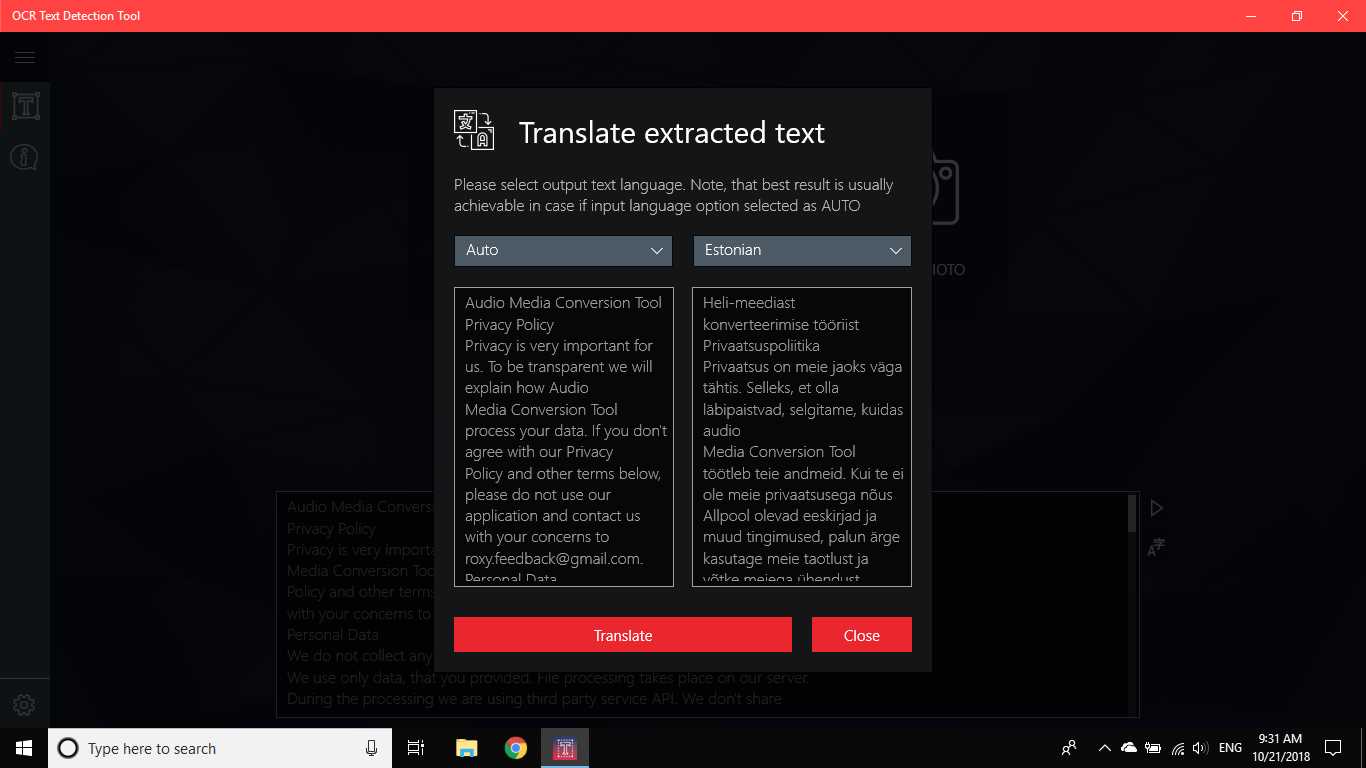
ابزار تشخیص متن OCR تشخیص دقیق و سریع متن را از هر پرونده تصویری که از دستگاه شما بارگیری شده است یا با یک عکس فوری گرفته شده فراهم می کند.همچنین از شناسایی متنی یک سند PDF پشتیبانی می کند (در حال حاضر بیش از 20 صفحه نیست ، اما ما در حال کار بر روی گسترش قابلیت ها هستیم).این نرم افزار همچنین از تشخیص دست خط و ترجمه متن در 114 زبان مختلف پشتیبانی می کند.طراحی دوستانه ، واضح و راحت کار با برنامه را آسان و قابل فهم می کند.* قالب های موجود: JPEG ، PNG8 ، PNG24 ، GIF ، GIF متحرک (فقط برای اولین بار قاب) ، BMP ، WEBP ، RAW ، ICO ، TIFF ، PDF (در حال حاضر بیش از 20 صفحه نیست ، اما ما در حال کار بر روی گسترش قابلیت ها هستیم) * متناز ویژگی های تشخیص قادر به تشخیص طیف گسترده ای از زبان ها است و می تواند چندین زبان را در یک تصویر واحد تشخیص دهد: آفریقایی (ع) ، عربی (ar) ، Assamese (ع) ، آذربایجانی (آز) ، بلاروس (be) ، بنگالی (bn)، بلغاری (bg) ، کاتالان (ca) ، چینی (zh *) ، کرواتی (hr) ، چک (cs) ، دانمارکی (دا) ، هلندی (nl) ، انگلیسی (en) ، استونیایی (et) ، فیلیپینی (filیا tl) ، فنلاندی (fi) ، فرانسوی (fr) ، آلمانی (د) ، یونانی (el) ، عبری (او یا iw) ، هندی (سلام) ، مجارستانی (هو) ، ایسلندی (است) ، اندونزیایی (id)، ایتالیایی (آن) ، ژاپنی (ja) ، قزاقستانی (kk) ، کره ای (ko) ، قرقیز (کی) ، لتونی (lv) ، لیتوانیایی (lt) ، مقدونی (mk) ، مراتی (mr) ، مغولی (mn)، نپالی (ne) ، نروژی (بدون) ، پشتو (ps) ، فارسی (fa) ، لهستانی (pl) ، پرتغالی (pt) ، رومانیایی (ro) ، روسی (ru) ، سانسکریت (sa) ، صربی (sr)، اسلواکیایی (sk) ، اسلوونیایی (sl) ، اسپانیایی (es) ، سوئدی (sv) ، تامیل (ta) ، تایلندی (هفتم) ، ترکی (tr) ، اوکراینی (UK) ، اردو (ur) ، ازبک (uz) ، ویتنامی (vi) این را بررسی کنید ، شما چیزی برای از دست دادن ندارید!
سایت اینترنتی:
https://www.microsoft.com/store/apps/9PL1PPFPT8VJامکانات
دسته بندی ها
گزینه های دیگر برای OCR Text Detection Tool برای Linux
71
35
GImageReader
gImageReader جلویی ساده Gtk / Qt به Tesseract OCR Engine است. ویژگی ها: - وارد کردن اسناد و تصاویر PDF از دیسک ، دستگاه های اسکن ، کلیپ بورد و تصاویر
9
8
6
5
5
4